



𝗪𝗵𝗮𝘁 𝗶𝘀 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴?
Survive and recover from failures

Resiliency Engineering is the practice of designing and building systems to achieve resiliency—ensuring they can handle failures, adapt to disruptions, and recover gracefully without major downtime.
“Anything that can go wrong will go wrong.”
- Murphy’s Law
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆?
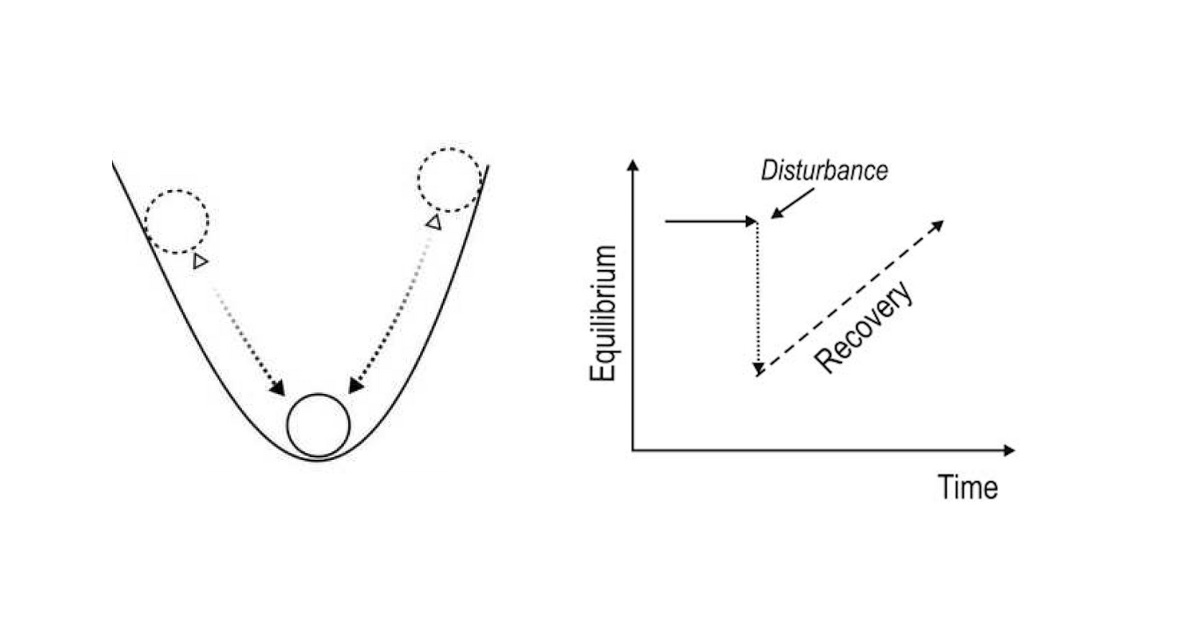
Before understanding Resiliency Engineering, it is necessary to understand what Resiliency is. Resiliency is an outcome, not a practice. It is the ability of a system to handle failures, adapt to disruptions, and maintain functionality under pressure
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴?
Resiliency Engineering is the practice of designing and building systems to achieve resiliency. It involves strategies like fault tolerance, redundancy, self-healing mechanisms, and failure recovery to ensure systems remain stable and reliable even in unpredictable conditions.
𝗧𝘆𝗽𝗲𝘀 𝗼𝗳 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴
Resiliency engineering can be broadly categorized into three types: proactive resiliency, reactive resiliency, adaptive resiliency.
𝗣𝗿𝗼𝗮𝗰𝘁𝗶𝘃𝗲 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆
Proactive resiliency prevents failures before they happen, keeping systems stable and reliable. It ensures smooth operations by distributing traffic, limiting overload, and maintaining backups. All are called Upstream Resiliency.
Load Balancing, Load Shedding & Load Leveling – Distribute traffic efficiently and prevent overload.
Throttling & Rate Limiting – Control excessive requests to maintain system stability.
Chaos Engineering – Inject controlled failures to test and improve system resilience.
Redundancy & Replication – Ensure backup systems are active to prevent downtime.
𝗥𝗲𝗮𝗰𝘁𝗶𝘃𝗲 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆
Reactive Resiliency ensures systems recover quickly with minimal impact when failures occur. All are called Downstream Resiliency.
Timeout - Setting a timeout ensures operations don’t hang indefinitely.
Retry Strategies & Retry Amplification – Reattempt failed operations with increasing delays to reduce strain and avoid simultaneous retries.
Fallback Plan & Failover Mechanisms – Offering alternative flows and switch to backup systems seamlessly.
Circuit Breakers – Prevent repeated failures from overwhelming services while avoiding unnecessary retries.
𝗔𝗱𝗮𝗽𝘁𝗶𝘃𝗲 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆
Adaptive Resiliency bridges Upstream and Downstream Resiliency by learning from failures and continuously improving system resilience.
Observability & Monitoring – Track failures in real time for better insights.
Chaos Engineering – Identify weaknesses and enhance system robustness.
Automated Scaling – Dynamically adjust resources based on demand.
Machine Learning & AI – Predict and prevent failures before they happen.
𝗖𝗼𝗿𝗲 𝗖𝗼𝗻𝗰𝗲𝗽𝘁𝘀 𝗼𝗳 𝗥𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝗰𝘆 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴
Building resilient systems requires key principles that ensure systems can withstand failures, adapt to disruptions, and recover quickly. These core concepts provide the foundation for designing resilient architectures.
To engineer resiliency, systems must be built with key principles:
Fault Tolerance – The ability to operate even when components fail
Redundancy – Backup systems that take over in case of failure.
Failover & Recovery – Mechanisms to switch to a working state quickly.
Observability & Monitoring – Real-time insights into system health.
Chaos Testing – Simulating failures to test system robustness.
𝗖𝗼𝗻𝗰𝗹𝘂𝘀𝗶𝗼𝗻
A truly resilient system integrates all three—proactively preventing failures, reacting gracefully when they occur, and continuously adapting to become stronger over time.
Resilience in distributed systems comes not from avoiding failure, but from embracing it—designing components to fail independently and recover gracefully.
Brendan Burns, Designing Distributed Systems
𝗜𝗻𝘀𝗽𝗶𝗿𝗮𝘁𝗶𝗼𝗻𝘀 𝗮𝗻𝗱 𝗥𝗲𝗳𝗲𝗿𝗲𝗻𝗰𝗲𝘀
Designing Distributed Systems, O’RELLY
Building Resilient Distributed Systems, O’RELLY
Understanding Distributed Systems, Roberto Vitillo.
Curious for more? Check out Resiliency Engineering FAQs for extra goodies!